Datasets in Nominal with Python
To use this guide, install the Nominal Python library with pip3 install nominal.
See Quickstart for more details.
Please contact us if you’re not sure whether your organization has access to Nominal.
Datasets are Nominal’s primitive for ingesting and working with tabular data files. They must have at least one timestamp column.
Once uploaded to Nominal, Datasets can be organized into Runs with other data sources - including video files, database connections, and log files.
Datasets are the file representation of Nominal’s Data Source primitive. Most often, Datasets are tabular files with at least one time dimension. Datasets can also be video files.
Head over to the Datasets page to see your organization’s most recently uploaded Datasets.
This guide details common patterns for working with Nominal Datasets in Python.
Connect to Nominal
To upload a Dataset, we’ll first have to connect to your Nominal platform tenant.
Concepts
- Base URL: The URL through which the Nominal API is accessed (typically
https://api.gov.nominal.io/api; shown under Settings → API keys). - Workspace: A mechanism by which to isolate datasets; each user has one or more workspace, and data in one cannot be seen from another. Note that a token / API key is attached to a user, and may access multiple workspaces.
- Profile: A combination of base URL, API key, and workspace.
There are two primary ways of authenticating the Nominal Client. The first is to use a profile stored on disk, and the second is to use a token directly.
Storing credentials to disk
Run the following in a terminal and follow on-screen prompts to set up a connection profile:
Here, “default” can be any name chosen to represent this profile (reminder: a profile represents a base URL, API key, and workspace).
The profile will be stored in ~/.config/nominal/config.yml, and can then be used to create a client:
If you have previously used nom to store credentials, prior to the availability of profiles, you will need to migrate your old configuration file (~/.nominal.yml) to the new format (~/.config/nominal/config.yml).
You can do this with the following command:
Directly using credentials in your scripts
NOTE: you should never share your Nominal API key with anyone. We therefore recommend that you not save it in your code and/or scripts.
Upload a Dataset
Replace frosty_flight_1k_rows.csv with a path to a CSV file on your own computer.
If you don’t have a CSV file handy, you can download ‘frosty_flight_1k_rows.csv’ by copy-pasting the below 4 lines into your Python terminal.
Head over to the CSV files page for more options for CSV file upload.
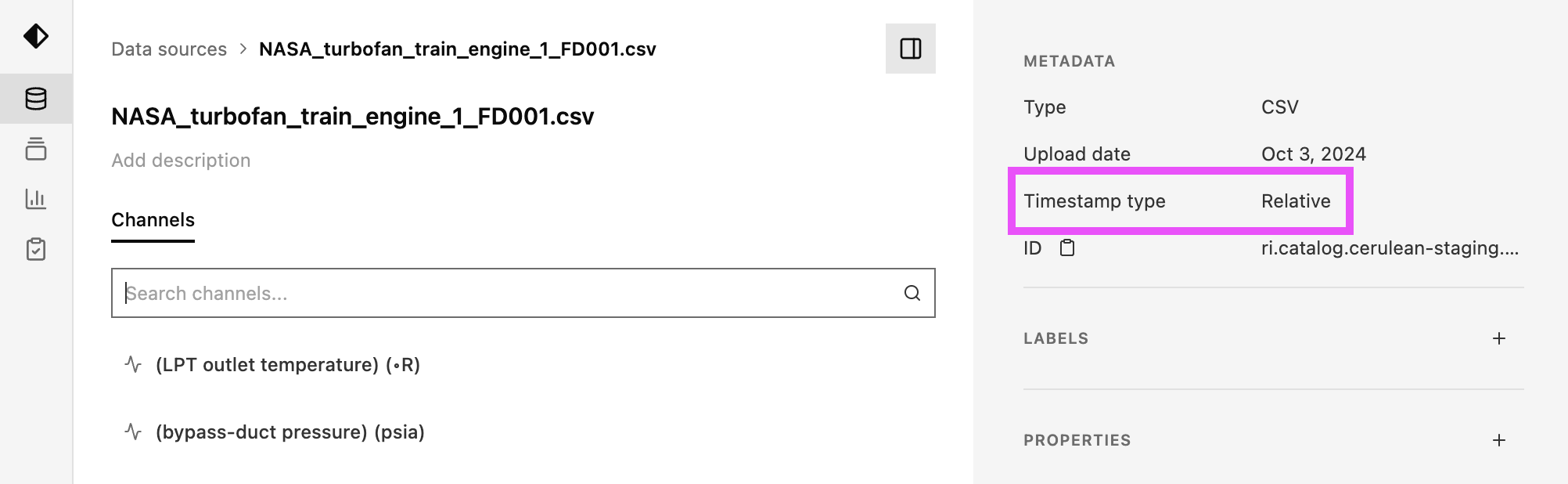
Relative timestamps
In the above example, we uploaded a Dataset with an absolute time series column (source_time).
In lay person’s terms, absolute times refers to the date + time on a calendar + clock when recording a measurement.
Absolute time is usually expressed in reference to a global standard
(such at UTC) that normalizes the
timestamp timezone.
Sometimes, test measurements are recorded in relative time, where 0 represents the start of the measurement and 0 + (i * time unit) represent the timestamp of subsequent measurements.
For example, say that you’re measuring the pressure in an engine chamber once per second. In relative time, your first measurement would be at time 0 and your 1000th measurement would be at 1000 seconds.
Nominal has first class support for measurements in either relative or absolute time, down to picosecond resolution.
To upload a dataset clocked in relative time, set the timestamp_type parameter to relative_seconds
(replace “seconds” with your measurement’s resolution - for example relative_hours, relative_microseconds,
relative_milliseconds, relative_minutes, or relative_nanoseconds).
Let’s look at this jet engine simulation from NASA.
The relative timestamp column is cycle, which represents one operational cycle of a jet engine.
(Nominal doesn’t have a relative_cycle timestamp type, so we’ll proxy with relative_hours).
First, let’s download and inspect this CSV:
The column that we’ll use for relative time, cycle, spans from 1 to 192.
Let’s look at all of the column names:
Finally, let’s upload this dataset to Nominal with timestamp_type set to relative:
Again, since Nominal doesn’t have a relative_cycle timestamp type (representing an operational cycle of a jet engine),
we’ve used relative_hours as a proxy.
If you navigate to your organization’s Datasets page, you’ll see this dataset at the top:

If you click on the dataset and inspect its metadata, you’ll see that the timestamp type is set to “relative:”
Acceptable values for timestamp_type include:
iso_8601,
epoch_days,
epoch_hours,
epoch_minutes,
epoch_seconds,
epoch_milliseconds,
epoch_microseconds,
epoch_nanoseconds,
relative_days,
relative_hours,
relative_minutes,
relative_seconds,
relative_milliseconds,
relative_microseconds,
relative_nanoseconds
Timestamps in the form 2024-06-08T05:58:42.000Z will have a timestamp_type of iso_8601.
Timestamps in the form 1581933170999989 will most likely be epoch_microseconds.
epoch_ timestamps refers to timestamps in Unix format.
For more information about Nominal timestamps in Python, see the
nominal.ts docs page.
Retrieve a Dataset
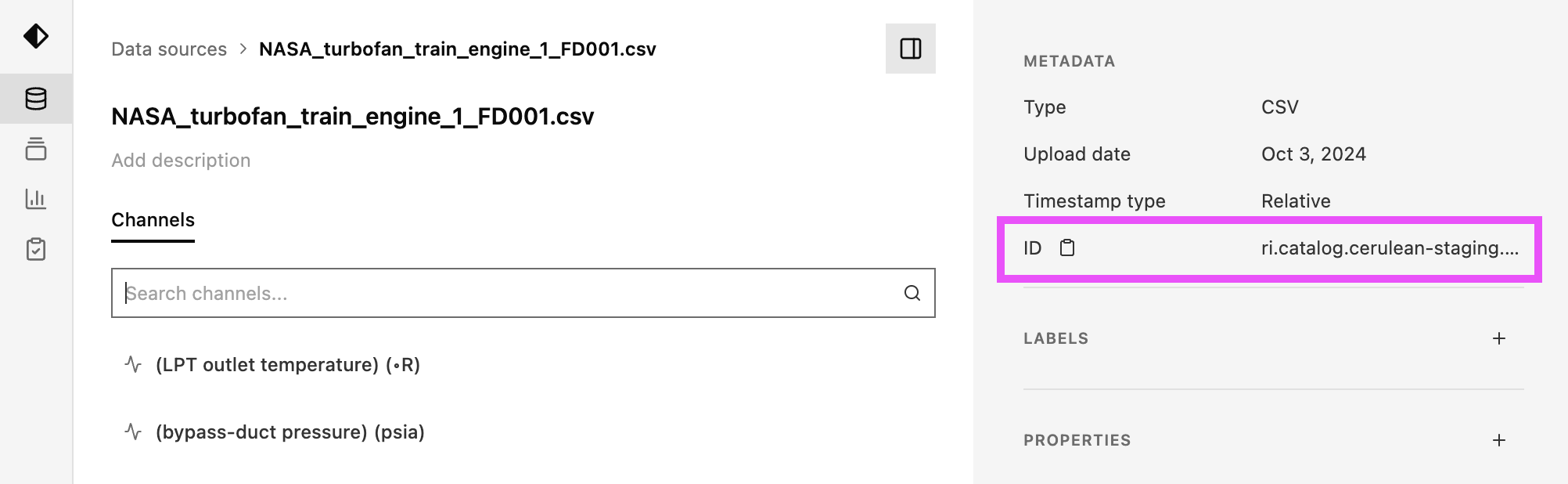
To download a Dataset on the Nominal platform, you’ll first need to obtain the Dataset’s resource identifier.
If you click on a Dataset from the Datasets page, you can copy/paste its RID from the metadata drawer:
Now that we have the Dataset RID, we can download it in Python with client.get_dataset(rid):
ds is a Dataset object
that contains the dataset’s metadata (name, description, labels, etc).
With the ds object that client.get_dataset(id) returns,
you can inspect the Dataset’s metadata, but not its actual data content. This capability will be included in an upcoming release.
All Nominal primitives (eg Datasets, Runs, Workbooks, and Checks) have a unique identifier called a “Resource ID”.
Resource IDs may be referred to as “RIDs”, or simply “IDs”, throughout the platform. They can be obtained from
a primitive’s detail page (or URL) and have a format that looks like ri.catalog.cerulean-staging.dataset.e5ede17b-05f9-404d-aaf5-ba85c99761a2.
Retrieve a Channel
🚧 This will be included in an upcoming release. Check back soon!
Set labels and properties
Let’s inspect the labels and properties of this dataset:
{'Fault Modes': 'HPC Degradation'}
('Simulation', 'NASA', 'Training data')
If we visit this dataset’s detail page, we’ll see these same labels and properties:

You can set a dataset’s labels and properties through the Dataset.update()
function.
For example, to remove a dataset’s labels and properties:
To set the dataset’s labels and properties back to their original values:
If you’re appending to a dataset’s labels or properties, you’ll want to cache the originals to not overwrite them:
Append to a Dataset
You can append to an existing dataset with a CSV that has the same columns.
For example, let’s download 1000 rows of this flight test data. We’ll split it into 2 dataframes that are 500 rows each and create a Nominal dataset with the first one:
Add the 2nd 500 rows with Dataset.add_csv_to_dataset().
Note that Dataset.add_csv_to_dataset()
only works for datasets with absolute (not relative) timestamps.
Update the dataset name as well:
You’re now familiar with the most common ways of interacting with Nominal’s Dataset primitive in Python.
For all methods available in the Dataset class, please see the Function Reference.