Object identification in Python
Object detection is crucial in autonomy and manufacturing for enhancing efficiency, safety, and precision. In autonomous systems like vehicles or robots, it enables real-time navigation, obstacle avoidance, and interaction with dynamic environments. In manufacturing, object detection facilitates automation by enabling machines to recognize, sort, and manipulate parts, improving quality control, productivity, and reducing human error.
Nominal has first class support for video ingestion, analysis, time synchronization across sensor channels, and automated checks that signal when a video feature is out-of-spec.
Connect to Nominal
Concepts
- Base URL: The URL through which the Nominal API is accessed (typically
https://api.gov.nominal.io/api; shown under Settings → API keys). - Workspace: A mechanism by which to isolate datasets; each user has one or more workspace, and data in one cannot be seen from another. Note that a token / API key is attached to a user, and may access multiple workspaces.
- Profile: A combination of base URL, API key, and workspace.
There are two primary ways of authenticating the Nominal Client. The first is to use a profile stored on disk, and the second is to use a token directly.
Storing credentials to disk
Run the following in a terminal and follow on-screen prompts to set up a connection profile:
Here, “default” can be any name chosen to represent this profile (reminder: a profile represents a base URL, API key, and workspace).
The profile will be stored in ~/.config/nominal/config.yml, and can then be used to create a client:
If you have previously used nom to store credentials, prior to the availability of profiles, you will need to migrate your old configuration file (~/.nominal.yml) to the new format (~/.config/nominal/config.yml).
You can do this with the following command:
Directly using credentials in your scripts
NOTE: you should never share your Nominal API key with anyone. We therefore recommend that you not save it in your code and/or scripts.
Download video files
For convenience, Nominal hosts sample test data on Hugging Face. To download the sample data for this guide, copy-paste the snippet below.
(Make sure to first install huggingface_hub with pip3 install huggingface_hub).
Since our dataset is a video file, we’ll rename dataset_path:
Display video
If you’re working in Jupyter notebook, here’s a shortcut to display the video inline in your notebook.
(For faster loading, only 20s of the full 225 MB video is shown above).
Inspect video metadata
After downloading the video, you can inspect its properties with OpenCV.
Download OpenCV with pip3 install opencv-python.
Extracted CV data
For convenience, the computer vision (“CV”) features extracted from this video are available on Nominal’s Hugging Face.
RT-DETR, a pre-trained ML model, was used to generate this data. If you’re interested in how to extract computer vision data for your own video, please see the Appendix.
Let’s download and inspect this data.
As you can see, each row of this table represents an object that the ML model (RT-DETR) identified.
Specifically, each row includes a label for the object identified, the video frame number, the object’s position within the frame, the video frame’s timestamp, and a count for all other objects identified in the same frame.
Let’s upload this data and video to Nominal for data review and automated check authoring.
Upload to Nominal
We’ll upload both the annotated video and extracted features dataset, then group them together as a Run.
In Nominal, Runs are time bounded views onto multimodal test data - including Datasets, Videos, Logs, and database connections.
To see your organization’s latest Runs, head over to the Runs page
Upload dataset
Since the extracted features CSV is already in a Polars
dataframe, we can conveniently upload it to Nominal with the upload_polars() function.
Upload video
We can upload the video file by creating an empty Video container
using
client.create_empty_video()
and then adding the video file with
Video.add_file_to_video().
First, however, we need to ensure that the video is in one of the formats that the platform accepts (MKV, MP4, MP2T).
For this step, you will need ffmpeg installed (see Correct video format).
Video upload requires a start time. If the start time of your video capture is not
important, you can choose an arbitrary time like datetime.now() or 2011-11-11 11:11:11.
Since Nominal uses timestamps to cross-correlate between datasets, make sure that
whichever start time you choose makes sense for the other datasets in the Run.
Create an empty Run
In Nominal, Runs are time bounded views onto multimodal test data - including Datasets, Videos, Logs, and database connections.
To see your organization’s latest Runs, head over to the Runs page
Set the Run start and end times with minimum and maximum values from the timestamp column.
Add dataset & video to Run
Add the video file and feature dataset to the Run with Run.add_datasets().
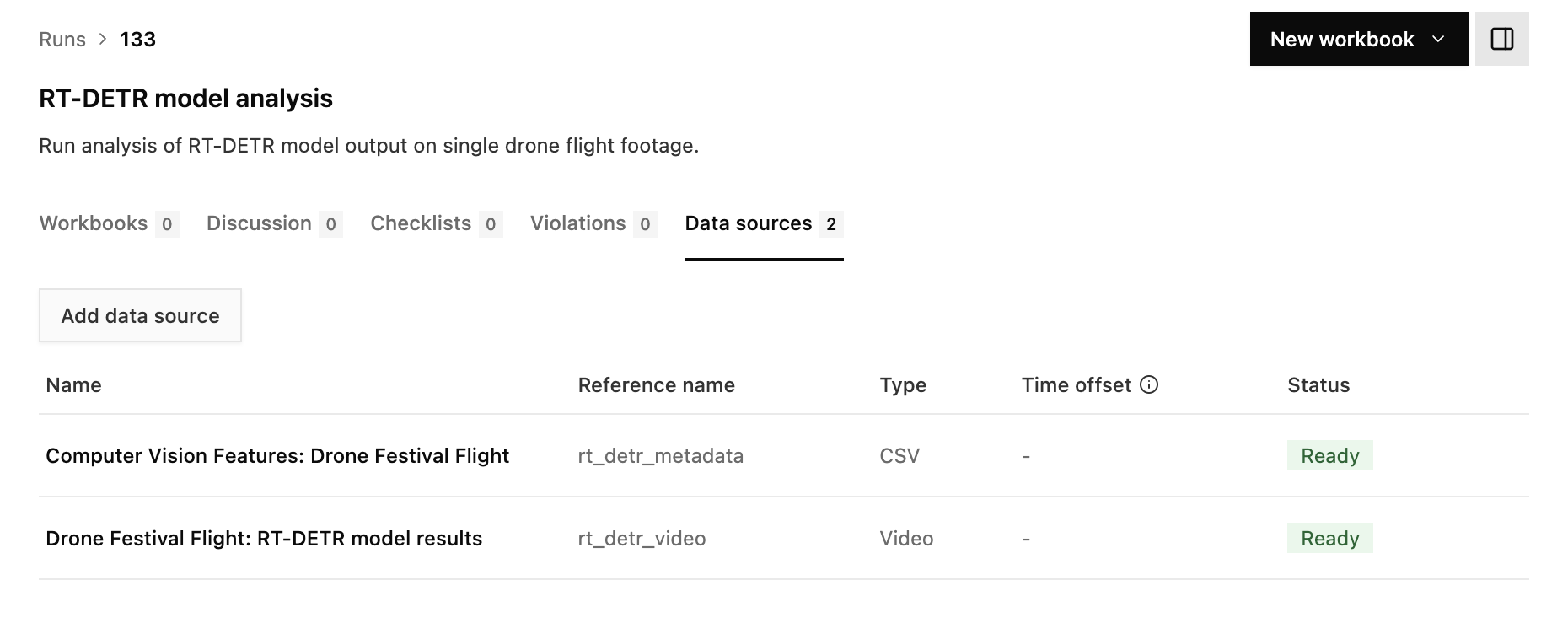
On the Nominal runs page, click on “RT-DETR model analysis” (login required). If you go to the “Data sources” tab of the run, you’ll now see the Video and CSV file associated with this run:
Create a workbook
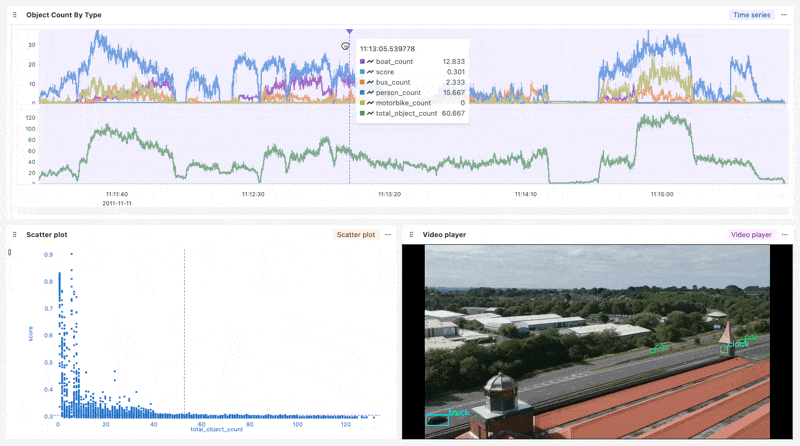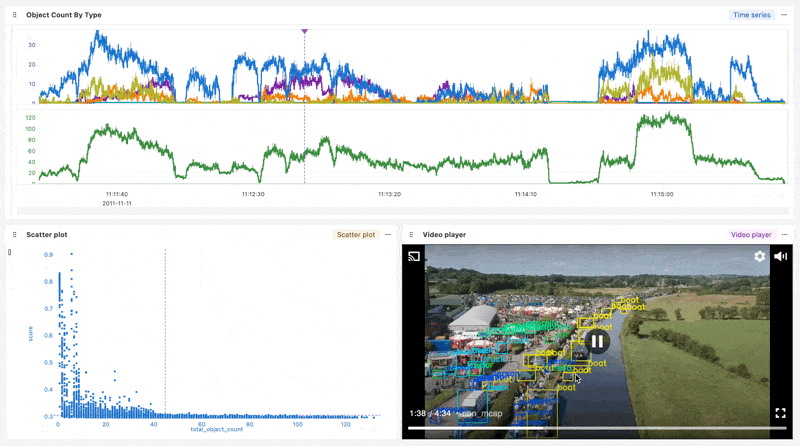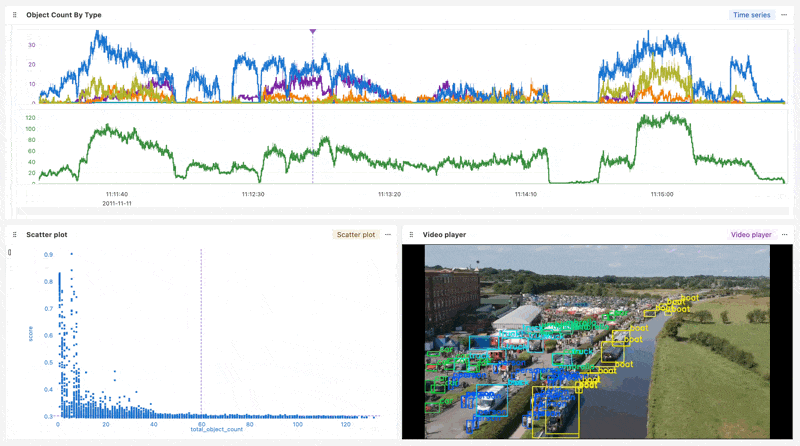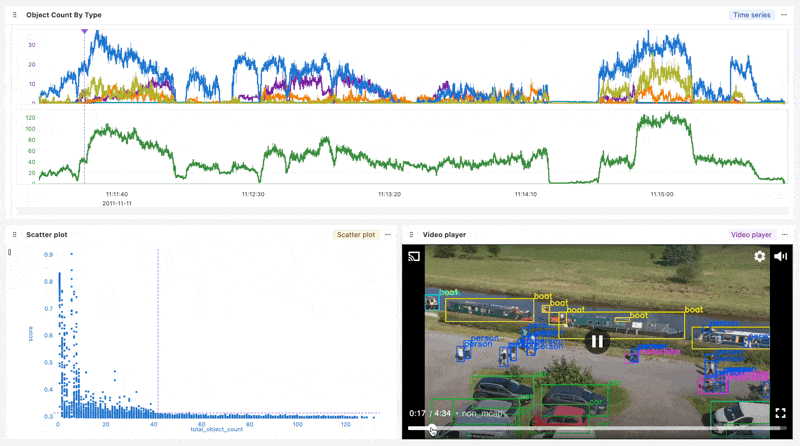
Now that your data is organized in a Run, it’s easy to create a Workbook for ad-hoc analysis on the Nominal platform.
This Workbook synchronizes the extracted feature data with the playback of the annotated video. Feature data like object count and ML model confidence score can be inspected frame-by-frame. Checks that signal anomalous behavior can also be defined and applied to future video ingests.
Workbook link (Login required)
Appendix
This section outlines the general steps for applying a pre-trained ML model to a video. The model chosen is RT-DETR - an object identification model. Other types of ML image models can be applied as well (such as depth detection, temperature analysis, etc). Choose an ML model or video analysis technique that is most helpful for your hardware testing goals. Please contact our team if you’d like to discuss!
For automating the ingestion of computer vision artifacts in Nominal, please see the previous section.
Identify objects per frame
The function below takes a PIL image and returns a Polars dataframe with all of the objects in the image identified.
We’ll use this function to step through the video frame-by-frame and identify each object.
Step through video frames
The below script steps through each frame in the video and uses get_objects_from_pil_image() (see above)
to identify each object. Each identified object is added as a row to the Polars dataframe df_video.
In less than 5 minutes of video, the RT-DETR model identified almost 300k objects!
Enrich metadata
The scripts below add timestamp and object count columns to df_video.
Timestamp column
df_video only has a frame count column. This script adds a timestamp column and
assigns each frame an absolute time (starting with ‘2011-11-11 11:11:11’ for the first frame).
Video start times are used to align playback with other time-domain data in your run. Whichever absolute start time that you choose for your video (for example, 2011-11-11 11:11:11), make sure that it aligns with the other start times in your run’s data sources.
Object count
The script below adds columns that count each object per video frame.
For example, if the boat_count column is 6, then 6 boats were identified in that frame.
Annotate video
Finally, the below script adds a color-coded bounding box and label to each object identified in each frame. The result is a fully annotated video.
(For faster loading, only 20s of the full 225 MB video is shown above).